


[ad_1]
This research aimed to construct a sports activities betting database to establish anomalies and detect match-fixing by way of betting odds knowledge. The database comprises knowledge on sports activities groups, match outcomes, and betting odds. A match-fixing detection mannequin was created based mostly on the database.
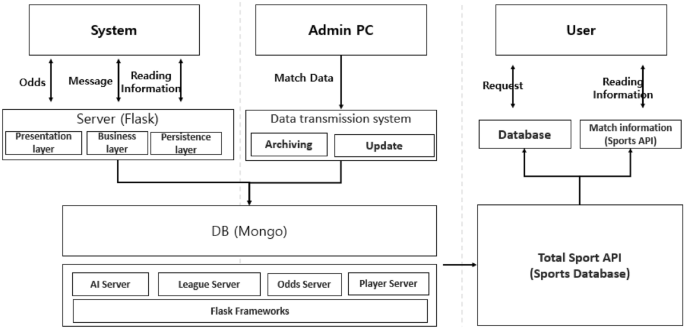
Sport database
The database was constructed on world soccer league match betting knowledge of 12 betting firms (188bet, Interwetten, Vcbet, 12bet, Willhill, Macauslot, Sbobet, Wewbet, Mansion88, Easybet, Bet365, and Crown), utilizing historic database documentation of iSports API. The latter offers an unlimited assortment of information on gamers, groups, recreation schedules, and league rankings for each sports activities league, together with soccer, basketball, baseball, hockey, and tennis. This research constructed a database utilizing knowledge on soccer matches. As proven in Desk 1, 31 sorts of knowledge had been collected. iSports API is a sports activities knowledge firm that provides software programming interfaces (APIs) for accessing and integrating sports activities knowledge into numerous platforms and functions. The API collects knowledge from a number of sources utilizing a mix of automated net scraping expertise, knowledge feeds, and partnerships with sports activities knowledge suppliers. To extract knowledge, net scraping strategies are utilized on sports activities web sites, together with official league and crew websites, information platforms, and sports activities statistics portals. As soon as gathered, the information are aggregated and introduced in a constant and structured format. This includes standardizing knowledge fields, normalizing knowledge codecs, and merging data from completely different sources to create complete and unified datasets. Moreover, high quality assurance measures are employed by iSports API to make sure the accuracy and reliability of the collected knowledge, enhancing its general reliability. The information collected by iSports API comprise match betting knowledge from numerous world soccer leagues, masking the interval from 2000 to 2020, together with knowledge from leagues, such because the Ok-League, Premier League, and Primera Liga. The dataset comprises odds for house matches, away matches, and ties, that are recorded at minute intervals all through every match.
The variables in Desk 1 represent the database, as proven in Fig. 1. The Flask server is obtainable for customers to request knowledge on betting odds, person messages, and matches. The Admin PC always updates match knowledge and shops them within the database. Database constructing happened in Mongo DB, offering the next servers: Sport Server on matches and climate; League Server on league and cup profiles, league rating, and occasions throughout matches; Odds Server on betting odds of various classes in addition to on betting firm web site; and Participant Server on participant’s efficiency, profile, and different data. The database, illustrated in Fig. 1, repeatedly collects soccer match knowledge, based mostly on 31 variables that have an effect on the result of the sport. This enables us to evaluate whether or not the derived match odds exhibit a standard or irregular sample, based mostly on numerous components. The database additionally allows the comparability of real-time knowledge on 31 variables and odds, thereby enabling the identification of irregular video games—each in actual time and retrospectively.
Betting fashions
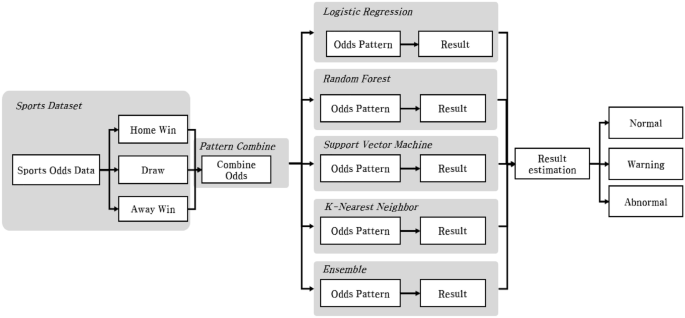
This research employed 4 fashions: assist vector machine (SVM), random forest (RF), logistic regression (LR), and k-nearest neighbor (KNN), recognized for his or her sturdy efficiency in classifying regular and irregular video games based mostly on win odds, tie odds, and lose odds patterns. As a substitute of solely counting on the patterns of regular and irregular video games recognized by these 4 distinct machine-learning fashions, we additional built-in them into an ensemble mannequin by aggregating their parameters. By pooling the predictions of all 5 fashions (the unique 4 plus the ensemble) by way of a voting mechanism, we categorized video games into three distinct patterns: “regular,” “warning,” and “irregular,” based mostly on the collective consensus of those fashions, The betting mannequin of this research will be described by Algorithm 1 as follows: A complete of 5 fashions had been used to detect irregular video games, together with 4 particular person machine studying fashions and one ensemble mannequin. The ensemble mannequin was based mostly on the parameters of the opposite 4 fashions. To find out the authenticity of a recreation, the outcomes of all 5 fashions had been aggregated. Moreover, a recreation was categorized into one of many following three classifications: “regular,” “warning,” or “irregular,” based mostly on the variety of fashions that recognized the sport as doubtlessly fraudulent. This complete dataset allowed us to establish patterns related to irregular matches, thereby enabling the classification mannequin to be taught and distinguish between regular and irregular labels. Therefore, the classification mannequin was employed as a way to successfully analyze and comprehend the intricacies throughout the dataset. The information used for classification had been employed to establish patterns of win odds, tie odds, and loss odds noticed in soccer matches, utilizing the proposed technique. These patterns had been then transformed into particular values and utilized within the classification course of. Thus, a particular sample of odds in soccer matches served as a mannequin variable.

Ensemble course of for detecting irregular video games
Developed a complicated multimodal synthetic intelligence mannequin designed to watch and analyze various kinds of knowledge for anomaly detection. The mannequin has a course of, proven in Fig. 2, that integrates enter from a number of sources and makes use of an ensemble strategy the place every submodel is specialised for a particular knowledge kind. The system combines insights from these submodels to evaluate the general scenario and categorizes the outcomes into completely different classes. The choice-making course of relies on a consensus mechanism28. If the vast majority of sub-models flag an occasion as suspicious, the occasion is labeled as ‘irregular.’ Consequently, the built-in mannequin is able to distinguishing between ‘regular’ and ‘irregular’ outcomes with excessive accuracy. To offer extra nuanced insights, the mannequin categorizes the anomalies into three ranges.

Betting anomaly detection course of.
For instance the general means of the mannequin, wish to detect anomalies within the odds knowledge of a single match. Subsequently, the percentages knowledge is classed into 5 fashions: 4 skilled fashions and an ensemble mannequin of 4 fashions. Right now, one odds knowledge is enter to 5 fashions as an enter worth, and every of the 5 fashions that acquired the information is judged as regular or irregular, and 5 outcomes are derived. Right now, if the depend of Irregular is 3 or extra, it’s Irregular, 2 is Warning, and 1 or much less is Regular. Subsequently, every of the 5 classification fashions derives two prediction labels, however the general mannequin counts two prediction labels and derives a complete of three outcomes.
-
1.
Regular: If the ‘Irregular Rely,’ which represents the variety of sub-models indicating an anomaly, is lower than 1, the scenario is judged as regular, indicating typical and secure operational situations.
-
2.
Warning: If the ‘Irregular Rely’ is strictly 2, it signifies a necessity for warning. This degree means that there may be potential points or rising dangers that require nearer monitoring or preventive measures.
-
3.
Irregular: If the ‘Irregular Rely’ is 3 or extra, the scenario is judged as irregular. This classification signifies a excessive chance of a big problem or anomaly that wants rapid consideration and probably corrective motion.
This complete dataset allowed us to establish patterns related to irregular matches, thereby enabling the classification mannequin to be taught and distinguish between regular and irregular labels. Therefore, the classification mannequin was employed as a way to successfully analyze and comprehend the intricacies throughout the dataset. The information used for classification had been employed to establish patterns of win odds, tie odds, and loss odds noticed in soccer matches, utilizing the proposed technique. These patterns had been then transformed into particular values and utilized within the classification course of.
Assist vector machine
An SVM is a knowledge classification mannequin that makes use of a call boundary to separate the information house into two disjoint half properties. New enter knowledge are categorised based mostly on their similarity to one in every of these properties. The bigger the boundary knowledge hole, the extra correct the classification mannequin. It’s, subsequently, widespread to arrange random outliers on either side of the choice boundary, often called margins. On this research, a most margin was created to boost classification accuracy, and the information coming into the margin had been eradicated29.
The SVM algorithm on the p-dimensional hyperplane is proven in Eq. (5), with (fleft( X proper) = 0).
$$fleft( X proper) = beta_{0} + beta_{1} X_{1} + cdots + beta_{p} X_{p}$$
(5)
$$fleft( X proper) = 0$$
(6)
The (fleft( X proper)) worth on the hyperplane is 1 (Class1) if (fleft( {X_{i} } proper) > 0), in any other case − 1 (Class2) if ((fleft( {X_{i} } proper) < 0)). Knowledge had been thought-about effectively sorted when the worth of Eq. (7) was constructive, following (Y_{i}) on (− 1, 1).
$$Y_{i} left( {beta_{0} + beta_{1} X_{i1} + cdots + beta_{p} X_{ip} } proper) > 0$$
(7)
With a hyperplane, as proven in Eq. (7), the information will be divided by completely different angles. Nevertheless, for a classification mannequin to be extremely correct, the hyperplane needs to be optimized by maximizing the margin between completely different knowledge factors. This results in discovering the utmost “M” (margin), as proven in Eq. (9). Consequently, the hyperplane and margin are designated whereas permitting errors (in_{i}) to some extent, earlier than eliminating all knowledge contained in the margin as outliers.
$$beta_{0} ,beta_{1} , ldots ,beta_{p} ,; in_{1} , ldots , in_{n} MMaximizeM$$
(8)
$$topic to mathop sum limits_{j = 1}^{p} ;;beta_{j}^{2} = 1$$
(9)
$$Y_{i} left( {beta_{0} + beta_{1} X_{i1} + cdots + beta_{p} X_{ip} } proper) ge Mleft( {1 – in_{1} } proper)$$
(10)
$$in_{1} ge 0, mathop sum limits_{i = 1}^{n} ;; in_{i} le C$$
(11)
For SVM mannequin, the C(Regularization Power) worth is 0.1 to stop overfitting, and because the values of the information are linear, the kernel is linear, and irregular matches of the percentages should not have common options, so RBF(Radial Foundation Operate) is adopted to derive such non-linear options30.
Random forest
Within the RF mannequin, determination bushes—the hierarchical construction composed of nodes and edges that join nodes—assist decide the optimum consequence. A call tree rotationally splits studying knowledge into subsets. This rotation-based division repeats on the divided subsets till there is no such thing as a extra predictive worth left, or the subset node’s worth turns into equivalent to the goal variable. This process is named the top-down induction of determination bushes (TDIDT), through which the dependent variable Y serves because the goal variable within the classification; moreover, vector v is expressed by Eq. (12).
$$left( {v, Y} proper) = left( {x_{1} ,x_{2} , ldots ,x_{d} , Y} proper)$$
(12)
Whereas classifying knowledge utilizing TDIDT, Gini impurity could also be used to measure misclassified knowledge in a set. Whereas randomly estimating the category, a set with a chance of misjudgment close to 0 is claimed to be pure. Subsequently, Gini impurity enhances the accuracy of the RF mannequin31.
$$I_{G} left( f proper) = mathop sum limits_{i = 1}^{m} f_{i} left( {1 – f_{i} } proper) = mathop sum limits_{i = 1}^{m} left( {f_{i} – f_{i}^{2} } proper) = mathop sum limits_{i = 1}^{m} f_{i} – mathop sum limits_{i = 1}^{m} f_{i}^{2} = 1 – mathop sum limits_{i = 1}^{m} f_{i}^{2}$$
(13)
Bushes are skilled to optimize break up operate parameters associated to inner nodes, in addition to end-node parameters, to attenuate outlined goal features when v (knowledge), S0 (skilled set), and actual knowledge labels are supplied. The RF mannequin optimizes and averages the choice tree outcomes utilizing the bagging technique earlier than classification. Bagging or bootstrap aggregation—that means concurrently bootstrapping a number of samples and aggregating outcomes from machine studying—is a technique that averages various fashions to establish the optimized model.
For the reason that variety of bushes determines the efficiency and accuracy of the LF mannequin, we ran Gridsearch with rising numbers of bushes, and located that the very best efficiency was achieved with 50 bushes. We additionally set the ratio to 0.4 to find out the utmost variety of options within the tree, and the utmost depth of the tree to 10 to stop overfitting32.
Logistic regression
LR is a supervised studying mannequin that predicts the likelihood of given knowledge belonging to a sure vary between 0 and 1. The goal variable is binary: 0–0.5 and 0.5–1. LR is linear, and every characteristic worth multiplied by a coefficient and added by the intercept provides log-odds towards the expected worth, enabling knowledge classification. Subsequently, the likelihood (P) of the occasion occurring or not occurring was calculated, and the log of the percentages was calculated for the classification by way of the ultimate worth33.
$$Odds = frac{{Pleft( {occasion occurring} proper)}}{{Pleft( {occasion not occurring} proper)}}$$
(14)
To guage the suitability of the outcomes to the mannequin, we should calculate and common the lack of the pattern. That is known as log loss, expressed in Eq. (15), which comprises the next components: m = complete variety of knowledge factors, y(i) = class for knowledge i, zi = log-odd of information i, and h(z(i)) = log-odds sigmoid that identifies a coefficient minimizing log loss, which provides the optimized mannequin.
$$- frac{1}{m}mathop sum limits_{i = 1}^{m} left[ {y^{left( i right)} loglog left( {hleft( {z^{left( i right)} } right)} right) + left( {1 – y^{left( i right)} } right)logleft( {1 – hleft( {z^{left( i right)} } right)} right)} right]$$
(15)
As soon as log-odds or property coefficient values had been calculated, they might be utilized to the sigmoid operate to calculate the result of the information, ranging between 0 and 1 and belonging to a given class. On this research, a loss operate was used to establish values close to 0 or 1, to type regular and irregular matches.
On this research, to search out the optimum hyperparameters for every of the 4 fashions, we used Gridsearch to fine-tune the weights of every mannequin and choose the mannequin with the optimum accuracy. For the LR mannequin, the C(Regularization Power) worth was set to 0.1 to stop overfitting, and to normalize the information values, Lasso regression evaluation was adopted, which may effectively decide the circulation of a particular match, and regularization was carried out utilizing liblinear, which is appropriate for small datasets for optimization34.
Ok-nearest neighbor
KNN is a classification algorithm of KNNs, based mostly on their knowledge label, utilizing the Euclidean distance components to guage the space. Primarily based on the Euclidean distance, d (distance) between A (x1, y1) and B (x2, y2) in a two-dimensional land is proven in Eq. (16).
$$dleft( {A,B} proper) = sqrt {(x_{2} – x_{1} )^{2} + (y_{2} – y_{1} )^{2} }$$
(16)
To differentiate between regular and irregular matches, the present research designated okay as 2 and break up array figures into regular or irregular matches utilizing the betting odds sample acceptable for every match35. On this research, we set okay = 2, because it includes the classification of two courses: regular and irregular. Consequently, the difficulty of ties can come up when an equal variety of nearest neighbors belong to completely different courses. To deal with this problem, the evaluation was carried out by augmenting mannequin stability by way of the utilization of k-fold cross-validation. This method allows the analysis of each the accuracy and stability of the classification mannequin, guaranteeing a extra sturdy and dependable classification end result for circumstances through which okay = 2. After figuring out the betting odds of a brand new match, the match array sample allowed us to find out whether or not it was extra regular or irregular. For the KNN mannequin, Gridsearch was carried out by adjusting the preliminary okay worth, and in consequence, okay = 2 was lastly adopted. As well as, Manhattan distance, Minkowski distance, and Euclidean distance had been used as distance metrics, however normal Euclidean distance was adopted because of the advanced nature of the information and the small variety of knowledge36.
Knowledge preprocessing
This research used hourly win-tie-loss betting odds knowledge to categorise irregular and regular matches. Ok-league soccer matches and match-fixing circumstances between 2000 and 2020 had been used as knowledge sources. The coaching knowledge, spanning 20 years, is derived from Ok-League soccer matches, the place every of the 12 groups performs 33 video games. Nevertheless, the dataset initially had a better depend of matches. Amongst these, a subset of matches was recognized as having static knowledge, characterised by minimal motion in betting odds as a consequence of low betting volumes. These matches had been excluded from our evaluation as a result of their static nature doesn’t present helpful insights for figuring out betting developments. Consequently, the refined dataset for coaching consists of two,607 knowledge factors. These factors characterize matches that attracted a big variety of bets, making them extra related for our evaluation in understanding betting patterns and developments. The educational knowledge had been based mostly on 2586 regular and 21 irregular matches. The matched dividend knowledge are proven in Fig. 3. On the x-axis, representing “Time,” a worth was assigned to every time circulation. The win-tie-loss betting odds worth was represented on the y-axis. Determine 3 is an instance of the time sequence circulation of odds for one out of 2607 video games. In Fig. 3, the x-axis represents the “Favourite” betting odds, suggesting the likelihood of a crew taking part in of their native stadium or one near their house base. Conversely, “Underdog” denotes the betting odds of a crew taking part in in an unfamiliar setting, doubtlessly impacted by numerous components comparable to completely different discipline dimensions, taking part in surfaces, and atmospheric situations. The “Tie” on the y-axis signifies the betting odds of each groups tying as a consequence of an equivalent rating within the match. Moreover, the x-axis represents the “Time” worth in minutes. Thus, the evolution of betting odds is depicted as a time sequence, capturing the percentages each earlier than the soccer recreation started and because it progressed.

Betting odds graph of matches (One among 2607 match knowledge).
For knowledge choice, utilizing matches not recognized as irregular might end in an inaccurate mannequin. Subsequently, solely matches confirmed as precise situations of abnormality within the Ok-League had been examined and utilized for coaching as irregular circumstances.
Earlier than studying, we checked whether or not the betting odds knowledge and size of every match had been irregular. As an illustration, there could also be 50 knowledge factors for match A and 80 factors for match B. In such a case, the distinction in knowledge dimensions hinders the mannequin’s studying course of. Subsequently, knowledge dimensions needs to be evened earlier than studying. Given the typical knowledge size of 80 to 100, the size of each dividend datum was adjusted to 100 in an analyzable type, earlier than smoothing and implementation by including a Sin worth. Determine 4 exhibits the information dimension adjustment to 100 with out altering the general betting odds graph sample and the appliance of the Sin-based smoothing. Superimposing a Sin wave onto our adjusted knowledge enabled us to focus on potential periodicities and improve the mannequin’s capability to seize these recurrent patterns. The Sin-based smoothing approach, when post-data dimension changes are utilized, emerges as an instrumental strategy, not solely guaranteeing the mitigation of unwarranted noise and fluctuations but in addition amplifying latent periodic developments, thereby selling knowledge uniformity throughout matches. This, in flip, cultivates an setting conducive for fashions to discern principal developments over outliers and enhances their functionality to generalize throughout various and unseen datasets, fortifying their general predictive proficiency37.

Knowledge dimension synchronization.
With the adjusted dimension of win-tie-loss betting odds knowledge, Fig. 5 represents an irregular match throughout studying, with no change in a given dividend. As proven in Fig. 4, every dimension was adjusted to the win-tie-loss betting odds knowledge. When studying every of the win-tie-loss betting odds, Fig. 5 represents an irregular match with no change in a given dividend, even for an irregular match. Nevertheless, its loss sample will be thought-about a standard match. Consequently, the educational mannequin will be thought-about a standard match when three completely different patterns are utilized concurrently.

Irregular match with each regular and irregular patterns.
To deal with this downside, datasets on win-tie-loss with a size of 100 every had been transformed to border a single dataset of 300 in size. Determine 6 exhibits the consequence. Three sorts of betting odds, proven in Fig. 5, had been mixed to type a sample, which in flip emphasised the traits of data-deprived irregular matches throughout studying.

Whole odds match dividend sample.
Irregular betting detection mannequin
An irregular match detection mannequin was developed based mostly on the information evaluation outcomes of every mannequin, utilizing the match consequence dividend knowledge. Primarily based on Fig. 7, the method begins with the real-time entry of information for every odds price throughout a sports activities recreation. This enter contains three odds classes: Favourite, Tie, and Underdog. Subsequently, the enter knowledge undergoes a change by way of the Sample Mix technique proposed on this research, ensuing within the era of a brand new sample. This newly derived sample is then fed into the 5 studying fashions. Every mannequin individually classifies video games as regular or irregular and offers corresponding outcomes. Consequently, the outcomes of the betting patterns are obtained for every mannequin, enabling a complete analysis of their efficiency. Primarily based on the betting sample evaluation outcomes from the 5 fashions, the irregular betting detection mannequin categorised matches based on the variety of irregular matches as follows: one or much less, regular; two, warning; three, hazard; and 4 or extra, irregular. Determine 7 exhibits the fashions’ classification course of, which offers a dividend sample to assist detect irregular matches. In abstract, we realized 4 machine studying fashions and created an ensemble mannequin utilizing the parameters of those 4 fashions, finally creating a complete of 5 fraud detection fashions. We categorised matches as regular, warning, harmful, or irregular based mostly on the variety of irregular matches detected by all 5 fashions, slightly than judging irregular matches based mostly on every mannequin’s outcomes.
Means of the irregular match detection mannequin.
Knowledge evaluation
The current research proceeded with machine studying utilizing 5 performant multiclass fashions: LR, RF, SVM, KNN, and the ensemble mannequin, which was an optimized model of the earlier 4 fashions. This was used to categorise regular and irregular matches by studying their sample from sports activities betting odds knowledge. This research utilized the win, tie, and loss odds estimated by the iSports API utilizing the 31 variables introduced in Desk 1.
Classification utilizing the 4 fashions and one ensemble mannequin used within the evaluation exhibits excessive efficiency in judging knowledge comparable to odds that should not have many variables. The accuracy of the coaching knowledge for every mannequin was 95% on common, and the loss worth was 0.05 on common, which is a excessive accuracy for the coaching knowledge. Subsequently, the mannequin was adopted to detect match-fixing.
As these 31 variables have an effect on the result of a soccer recreation, they weren’t immediately employed as knowledge; slightly, their affect was mirrored within the derived odds. Subsequently, the percentages variables for wins, ties, and losses had been employed on this research. The dataset was sorted chronologically for wins, ties, and losses, no matter CompanyID (a variable used to distinguish and categorize the betting firms), and in circumstances of equivalent timestamps, averages had been utilized. Desk 2 offers a proof of the information subset. We collected betting knowledge from three days earlier than the beginning of the sport till the tip of the sport. Knowledge assortment occurred each time there was a change in Favourite, Tie, or Underdog betting knowledge, with out specifying a hard and fast time interval. Desk 2 offers an in depth description of the variables used on this context. ScheduleID is a variable used to distinguish and establish particular matches. It permits us to tell apart particulars such because the match date and the groups concerned within the recreation. On this analysis, CompanyID was utilized as a variable to tell apart amongst 12 completely different betting firms. Favourite, Tie, and Underdog characterize betting knowledge for wins, ties, and losses, based mostly on the house crew. These variables represent the first knowledge used on this research, reflecting real-time modifications in betting knowledge. ModifyTime is a variable that data the time when knowledge modifications occurred. For instance, if there have been modifications in betting knowledge from Firm A, the modified Favourite, Tie, and Underdog knowledge could be recorded together with the time of the modification. If Firm A skilled modifications in betting knowledge whereas Firm B didn’t, solely the modified betting knowledge from Firm A could be recorded.
This research course of includes testing 5 fashions utilizing a dataset that consists of 2607 gadgets. This dataset is utilized for studying functions, comprising 2586 regular matches and 21 irregular matches. For the validation section, a separate set of 20 matches is employed, which is evenly divided into 10 regular and 10 irregular matches. This setup ensures that the fashions are each skilled on a complete dataset after which precisely validated utilizing a balanced mixture of regular and irregular match knowledge. Acknowledge that the dataset in our research could also be perceived as restricted in amount; nevertheless, as we take care of betting knowledge on uncommon matches, in follow, we can not use knowledge with out verified situations of matches with unlawful odds for coaching. It is because if the mannequin is skilled with irregular match odds which are truly from a standard match, there’s a downside. Subsequently, solely knowledge verified with precise circumstances had been used. Though the scale of the educational dataset is small, it comprises all of the patterns of unlawful/irregular video games that happen inside it; subsequently, it represents the phenomenon or sample studied on this analysis. The RF, KNN, and ensemble fashions recorded a excessive accuracy of over 92%, whereas the LR and SVM fashions had been roughly 80% correct (Desk 3).
[ad_2]
Source link



{kind=link}